Chomsky Hierarchy
Chomsky Hierarchy represents the class of languages that are
accepted by the different machine. The category of language in Chomsky's
Hierarchy is as given below:
- Type
0 known as Unrestricted Grammar.
- Type
1 known as Context Sensitive Grammar.
- Type
2 known as Context Free Grammar.
- Type
3 Regular Grammar.
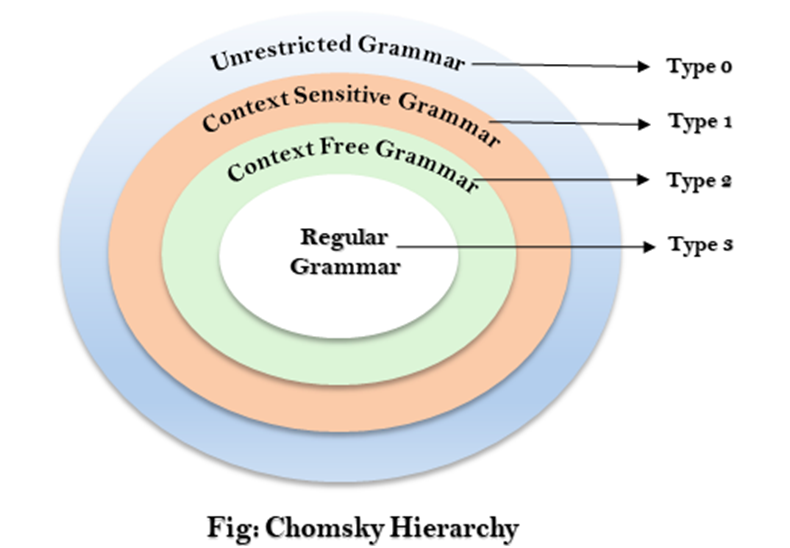
This
is a hierarchy. Therefore every language of type 3 is also of type 2, 1 and 0.
Similarly, every language of type 2 is also of type 1 and type 0, etc.
Type 0 Grammar:
Type 0 grammar is known as
Unrestricted grammar. There is no restriction on the grammar rules of these
types of languages. These languages can be efficiently modeled by Turing
machines.
For example:
1. bAa → aa
2. S → s
Type 1 Grammar:
Type 1 grammar is known as
Context Sensitive Grammar. The context sensitive grammar is used to represent
context sensitive language. The context sensitive grammar follows the following
rules:
- The context sensitive grammar may have more than one symbol on the left hand side of their production rules.
- The number of symbols on the left-hand side must not exceed the number of symbols on the right-hand side.
- The rule of the form A → ε is not allowed unless A is a start symbol. It does not occur on the right-hand side of any rule.
- The Type 1 grammar should be Type 0. In type 1, Production is in the form of V → T
Where the count of symbol in V is
less than or equal to T.
For example:
1. S → AT
2. T → xy
3. A → a
Type 2 Grammar:
Type 2 Grammar is known as
Context Free Grammar. Context free languages are the languages which can be
represented by the context free grammar (CFG). Type 2 should be type 1. The
production rule is of the form
1. A → α
Where A is any single
non-terminal and is any combination of terminals and non-terminals.
For example:
1. A → aBb
2. A → b
3. B → a
Type 3 Grammar:
Type 3 Grammar is known as
Regular Grammar. Regular languages are those languages which can be described
using regular expressions. These languages can be modeled by NFA or DFA.
Type 3 is most restricted form of
grammar. The Type 3 grammar should be Type 2 and Type 1. Type 3 should be in
the form of
1. V → T*V / T*
For example:
1. A → xy

